mirror of
https://github.com/modelscope/FunASR
synced 2025-09-15 14:48:36 +08:00
361 lines
12 KiB
Markdown
361 lines
12 KiB
Markdown
# FunASR-1.x.x Registration Tutorial
|
||
|
||
The original intention of the funasr-1.x.x version is to make model integration easier. The core feature is the registry and AutoModel:
|
||
|
||
* The introduction of the registry enables the development of building blocks to access the model, compatible with a variety of tasks;
|
||
|
||
* The newly designed AutoModel interface unifies modelscope, huggingface, and funasr inference and training interfaces, and supports free download of repositories;
|
||
|
||
* Support model export, demo-level service deployment, and industrial-level multi-concurrent service deployment;
|
||
|
||
* Unify academic and industrial model inference training scripts;
|
||
|
||
|
||
# Quick to get started
|
||
|
||
## AutoModel usage
|
||
|
||
### SenseVoiceSmall 模型
|
||
|
||
Input any length of voice, the output as the voice content corresponding to the text, the text has punctuation broken sentences, support Chinese, English, Japanese, Guangdong, Korean and 5 Chinese languages. \[Word-level timestamp and speaker identity\] will be supported later.
|
||
|
||
```python
|
||
from funasr import AutoModel
|
||
from funasr.utils.postprocess_utils import rich_transcription_postprocess
|
||
|
||
model = AutoModel(
|
||
model="iic/SenseVoiceSmall",
|
||
vad_model="fsmn-vad",
|
||
vad_kwargs={"max_single_segment_time": 30000},
|
||
device="cuda:0",
|
||
)
|
||
|
||
res = model.generate(
|
||
input=f"{model.model_path}/example/en.mp3",
|
||
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
|
||
use_itn=True,
|
||
batch_size_s=60,
|
||
)
|
||
text = rich_transcription_postprocess(res[0]["text"])
|
||
print(text) #👏Senior staff, Priipal Doris Jackson, Wakefield faculty, and, of course, my fellow classmates.I am honored to have been chosen to speak before my classmates, as well as the students across America today.
|
||
```
|
||
|
||
## API documentation
|
||
|
||
#### Definition of AutoModel
|
||
|
||
```plaintext
|
||
Model = AutoModel(model=[str], device=[str], ncpu=[int], output_dir=[str], batch_size= [int], hub=[str], **quargs)
|
||
```
|
||
|
||
* `model`(str): [Model Warehouse](https://github.com/alibaba-damo-academy/FunASR/tree/main/model_zoo)The model name in, or the model path in the local disk
|
||
|
||
* `device`(str): `cuda:0`(Default gpu0), using GPU for inference, specified. If`cpu`Then the CPU is used for inference
|
||
|
||
* `ncpu`(int): `4`(Default), set the number of threads used for CPU internal operation parallelism
|
||
|
||
* `output_dir`(str): `None`(Default) If set, the output path of the output result
|
||
|
||
* `batch_size`(int): `1`(Default), batch processing during decoding, number of samples
|
||
|
||
* `hub`(str):`ms`(Default) to download the model from modelscope. If`hf`To download the model from huggingface.
|
||
|
||
* `**kwargs`(dict): All in`config.yaml`Parameters, which can be specified directly here, for example, the maximum cut length in the vad model.`max_single_segment_time=6000`(Milliseconds).
|
||
|
||
|
||
#### AutoModel reasoning
|
||
|
||
```plaintext
|
||
Res = model.generate(input=[str], output_dir=[str])
|
||
```
|
||
|
||
* * wav file path, for example: asr\_example.wav
|
||
|
||
* pcm file path, for example: asr\_example.pcm, you need to specify the audio sampling rate fs (default is 16000)
|
||
|
||
* Audio byte stream, for example: microphone byte data
|
||
|
||
* wav.scp,kaldi-style wav list (`wav_id \t wav_path`), for example:
|
||
|
||
|
||
```plaintext
|
||
Asr_example1./audios/asr_example1.wav
|
||
Asr_example2./audios/asr_example2.wav
|
||
|
||
```
|
||
|
||
In this input
|
||
|
||
* Audio sampling points, for example:`audio, rate = soundfile.read("asr_example_zh.wav")`Is numpy.ndarray. batch input is supported. The type is list:`[audio_sample1, audio_sample2, ..., audio_sampleN]`
|
||
|
||
* fbank input, support group batch. shape is \[batch, frames, dim\], type is torch.Tensor, for example
|
||
|
||
* `output_dir`: None (default), if set, the output path of the output result
|
||
|
||
* `**kwargs`(dict): Model-related inference parameters, e.g,`beam_size=10`,`decoding_ctc_weight=0.1`.
|
||
|
||
|
||
Detailed documentation link:[https://github.com/modelscope/FunASR/blob/main/examples/README\_zh.md](https://github.com/modelscope/FunASR/blob/main/examples/README_zh.md)
|
||
|
||
# Registry Details
|
||
|
||
Take the SenseVoiceSmall model as an example, explain how to register a new model, model link:
|
||
|
||
**modelscope:**[https://www.modelscope.cn/models/iic/SenseVoiceSmall/files](https://www.modelscope.cn/models/iic/SenseVoiceSmall/files)
|
||
|
||
**huggingface:**[https://huggingface.co/FunAudioLLM/SenseVoiceSmall](https://huggingface.co/FunAudioLLM/SenseVoiceSmall)
|
||
|
||
## Model Resource Catalog
|
||
|
||
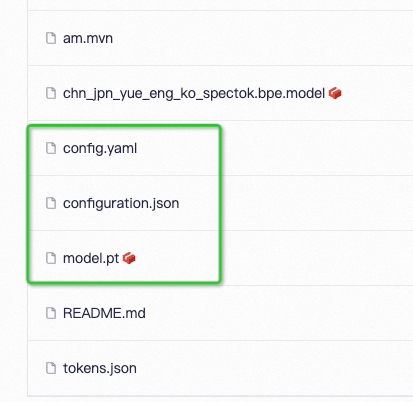
|
||
|
||
Configuration File: config.yaml
|
||
|
||
```yaml
|
||
encoder: SenseVoiceEncoderSmall
|
||
encoder_conf:
|
||
output_size: 512
|
||
attention_heads: 4
|
||
linear_units: 2048
|
||
num_blocks: 50
|
||
tp_blocks: 20
|
||
dropout_rate: 0.1
|
||
positional_dropout_rate: 0.1
|
||
attention_dropout_rate: 0.1
|
||
input_layer: pe
|
||
pos_enc_class: SinusoidalPositionEncoder
|
||
normalize_before: true
|
||
kernel_size: 11
|
||
sanm_shfit: 0
|
||
selfattention_layer_type: sanm
|
||
|
||
|
||
model: SenseVoiceSmall
|
||
model_conf:
|
||
length_normalized_loss: true
|
||
sos: 1
|
||
eos: 2
|
||
ignore_id: -1
|
||
|
||
tokenizer: SentencepiecesTokenizer
|
||
tokenizer_conf:
|
||
bpemodel: null
|
||
unk_symbol: <unk>
|
||
split_with_space: true
|
||
|
||
frontend: WavFrontend
|
||
frontend_conf:
|
||
fs: 16000
|
||
window: hamming
|
||
n_mels: 80
|
||
frame_length: 25
|
||
frame_shift: 10
|
||
lfr_m: 7
|
||
lfr_n: 6
|
||
cmvn_file: null
|
||
|
||
|
||
dataset: SenseVoiceCTCDataset
|
||
dataset_conf:
|
||
index_ds: IndexDSJsonl
|
||
batch_sampler: EspnetStyleBatchSampler
|
||
data_split_num: 32
|
||
batch_type: token
|
||
batch_size: 14000
|
||
max_token_length: 2000
|
||
min_token_length: 60
|
||
max_source_length: 2000
|
||
min_source_length: 60
|
||
max_target_length: 200
|
||
min_target_length: 0
|
||
shuffle: true
|
||
num_workers: 4
|
||
sos: ${model_conf.sos}
|
||
eos: ${model_conf.eos}
|
||
IndexDSJsonl: IndexDSJsonl
|
||
retry: 20
|
||
|
||
train_conf:
|
||
accum_grad: 1
|
||
grad_clip: 5
|
||
max_epoch: 20
|
||
keep_nbest_models: 10
|
||
avg_nbest_model: 10
|
||
log_interval: 100
|
||
resume: true
|
||
validate_interval: 10000
|
||
save_checkpoint_interval: 10000
|
||
|
||
optim: adamw
|
||
optim_conf:
|
||
lr: 0.00002
|
||
Scheduler: warmuplr
|
||
Scheduler_conf:
|
||
Warmup_steps: 25000
|
||
|
||
```
|
||
|
||
Model parameters: model.pt
|
||
|
||
Path resolution: configuration.json (not required)
|
||
|
||
```json
|
||
{
|
||
"framework": "pytorch",
|
||
"task" : "auto-speech-recognition",
|
||
"model": {"type" : "funasr"},
|
||
"pipeline": {"type":"funasr-pipeline"},
|
||
"model_name_in_hub": {
|
||
"ms":"",
|
||
"hf":""},
|
||
"file_path_metas": {
|
||
"init_param":"model.pt",
|
||
"config":"config.yaml",
|
||
"tokenizer_conf": {"bpemodel": "chn_jpn_yue_eng_ko_spectok.bpe.model"},
|
||
"frontend_conf":{"cmvn_file": "am.mvn"}}
|
||
}
|
||
```
|
||
|
||
The function of configuration.json is to add the model root directory to the item in file\_path\_metas, so that the path can be correctly parsed. For example, assume that the model root directory is:/home/zhifu.gzf/init\_model/SenseVoiceSmall,The relevant path in config.yaml in the directory is replaced with the correct path (ignoring irrelevant configuration):
|
||
|
||
```yaml
|
||
init_param: /home/zhifu.gz F/init_model/sensevoicemail Mall/model.pt
|
||
|
||
tokenizer_conf:
|
||
bpemodel: /home/Zhifu.gzf/init_model/SenseVoiceSmall/chn_jpn_yue_eng_ko_spectok.bpe.model
|
||
|
||
frontend_conf:
|
||
cmvn_file: /home/zhifu.Gzf/init_model/SenseVoiceSmall/am.mvn
|
||
```
|
||
|
||
## Registry
|
||
|
||
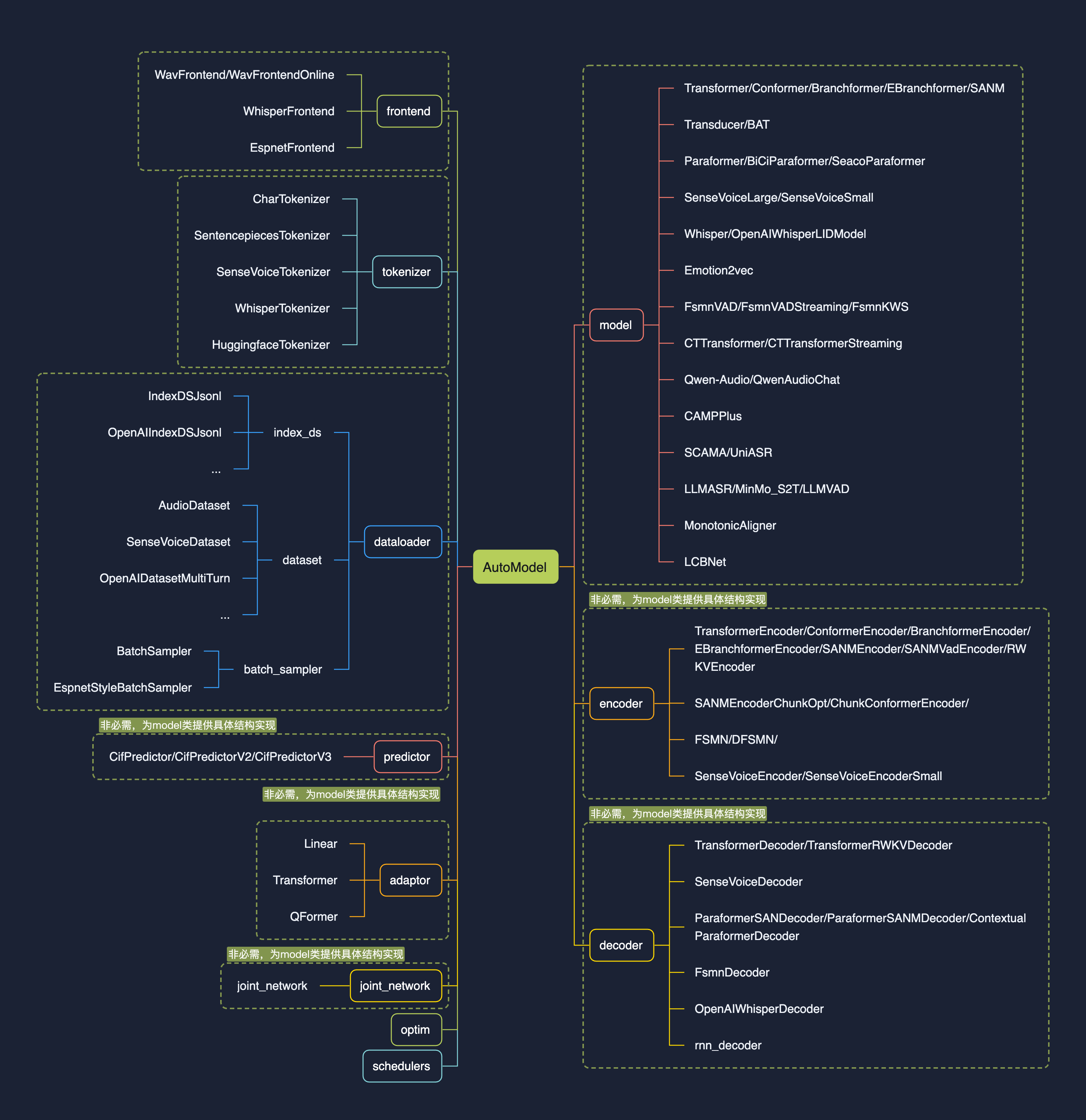
|
||
|
||
### View Registry
|
||
|
||
```plaintext
|
||
from funasr.register import tables
|
||
|
||
tables.print()
|
||
```
|
||
|
||
Support to view the specified type of Registry: 'tables.print("model")', currently funasr has registered model as shown in the figure above. The following categories are currently predefined:
|
||
|
||
```python
|
||
model_classes = {}
|
||
frontend_classes = {}
|
||
specaug_classes = {}
|
||
normalize_classes = {}
|
||
encoder_classes = {}
|
||
decoder_classes = {}
|
||
joint_network_classes = {}
|
||
predictor_classes = {}
|
||
stride_conv_classes = {}
|
||
tokenizer_classes = {}
|
||
dataloader_classes = {}
|
||
batch_sampler_classes = {}
|
||
dataset_classes = {}
|
||
index_ds_classes = {}
|
||
```
|
||
|
||
### Registration Model
|
||
|
||
```python
|
||
from funasr.register import tables
|
||
|
||
@tables.register("model_classes", "SenseVoiceSmall")
|
||
class SenseVoiceSmall(nn.Module):
|
||
def __init__(*args, **kwargs):
|
||
...
|
||
|
||
def forward(
|
||
self,
|
||
**kwargs,
|
||
):
|
||
|
||
def inference(
|
||
self,
|
||
data_in,
|
||
data_lengths=None,
|
||
key: list = None,
|
||
tokenizer=None,
|
||
frontend=None,
|
||
**kwargs,
|
||
):
|
||
...
|
||
|
||
```
|
||
|
||
Add @ tables.register("model\_classes", "SenseVoiceSmall") before the name of the class to be registered. The class needs to implement the following methods:\_\_init \_\_, forward, and inference.
|
||
|
||
register Usage:
|
||
|
||
```python
|
||
@ tables.register("registration classification", "registration name")
|
||
```
|
||
|
||
Among them, "registration classification" can be a predefined classification (see the figure above). If it is a new classification defined by oneself, the new classification will be automatically written into the registry classification. "registration name" means the name you want to register and can be used directly in the future.
|
||
|
||
Full code:[https://github.com/modelscope/FunASR/blob/main/funasr/models/sense\_voice/model.py#L443](https://github.com/modelscope/FunASR/blob/main/funasr/models/sense_voice/model.py#L443)
|
||
|
||
After the registration is complete, specify the new registration model in config.yaml to define the model.
|
||
|
||
```python
|
||
model: SenseVoiceSmall
|
||
model_conf:
|
||
...
|
||
```
|
||
|
||
### Registration failed
|
||
|
||
If the registration model or method is not found, assert model\_class is not None, f'{kwargs\["model"\]} is not registered '. The principle of model registration is to import the model file,You can view the specific reason for the registration failure through import. For example, the preceding model file is funasr/models/sense\_voice/model.py:
|
||
|
||
```python
|
||
from funasr.models.sense_voice.model import *
|
||
```
|
||
|
||
## Principles of Registration
|
||
|
||
* Model: models are independent of each other. Each Model needs to create a new Model directory under funasr/models/. Do not use class inheritance method!!! Do not import from other model directories, and put everything you need into your own model directory!!! Do not modify the existing model code!!!
|
||
|
||
* dataset,frontend,tokenizer, if you can reuse the existing one, reuse it directly, if you cannot reuse it, please register a new one, modify it again, and do not modify the original one!!!
|
||
|
||
|
||
# Independent warehouse
|
||
|
||
It can exist as a stand-alone repository for code secrecy, or as a stand-alone open source. Based on the registration mechanism, you do not need to integrate it into funasr. You can also use funasr for inference, and you can also directly perform inference. finetune is also supported.
|
||
|
||
**Using AutoModel for inference**
|
||
|
||
```python
|
||
from funasr import AutoModel
|
||
|
||
# trust_remote_code:'True' means that the model code implementation is loaded from 'remote_code', 'remote_code' specifies the location of the 'model' specific code (for example,'model.py') in the current directory, supports absolute and relative paths, and network url.
|
||
model = AutoModel (
|
||
model="iic/SenseVoiceSmall ",
|
||
trust_remote_code=True
|
||
remote_code = "./model.py",
|
||
)
|
||
```
|
||
|
||
**Direct inference**
|
||
|
||
```python
|
||
from model import SenseVoiceSmall
|
||
|
||
m, kwargs = SenseVoiceSmall.from_pretrained(model="iic/SenseVoiceSmall")
|
||
m.eval()
|
||
|
||
res = m.inference(
|
||
data_in=f"{kwargs ['model_path']}/example/en.mp3",
|
||
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
|
||
use_itn=False,
|
||
ban_emo_unk=False,
|
||
**kwargs,
|
||
)
|
||
|
||
print(text)
|
||
```
|
||
|
||
Trim reference:[https://github.com/FunAudioLLM/SenseVoice/blob/main/finetune.sh](https://github.com/FunAudioLLM/SenseVoice/blob/main/finetune.sh) |