mirror of
https://github.com/modelscope/FunASR
synced 2025-09-15 14:48:36 +08:00
funasr tables
This commit is contained in:
parent
e6fe606577
commit
7900433640
@ -7,6 +7,7 @@ FunASR开源了大量在工业数据上预训练模型,您可以在 [模型许
|
||||
<a href="#模型推理"> 模型推理 </a>
|
||||
|<a href="#模型训练与测试"> 模型训练与测试 </a>
|
||||
|<a href="#模型导出与测试"> 模型导出与测试 </a>
|
||||
|<a href="#新模型注册教程"> 新模型注册教程 </a>
|
||||
</h4>
|
||||
</div>
|
||||
|
||||
@ -434,3 +435,57 @@ print(result)
|
||||
```
|
||||
|
||||
更多例子请参考 [样例](https://github.com/alibaba-damo-academy/FunASR/tree/main/runtime/python/onnxruntime)
|
||||
|
||||
<a name="新模型注册教程"></a>
|
||||
## 新模型注册教程
|
||||
|
||||
|
||||
### 查看注册表
|
||||
|
||||
```python
|
||||
from funasr.register import tables
|
||||
|
||||
tables.print()
|
||||
```
|
||||
|
||||
支持查看指定类型的注册表:`tables.print("model")`
|
||||
|
||||
|
||||
### 注册新模型
|
||||
|
||||
```python
|
||||
from funasr.register import tables
|
||||
|
||||
@tables.register("model_classes", "MinMo_S2T")
|
||||
class MinMo_S2T(nn.Module):
|
||||
def __init__(*args, **kwargs):
|
||||
...
|
||||
|
||||
def forward(
|
||||
self,
|
||||
**kwargs,
|
||||
):
|
||||
|
||||
def inference(
|
||||
self,
|
||||
data_in,
|
||||
data_lengths=None,
|
||||
key: list = None,
|
||||
tokenizer=None,
|
||||
frontend=None,
|
||||
**kwargs,
|
||||
):
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
然后在config.yaml中指定新注册模型
|
||||
|
||||
```yaml
|
||||
model: MinMo_S2T
|
||||
model_conf:
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
[更多详细教程文档](https://github.com/alibaba-damo-academy/FunASR/docs/tutorial/Tables_zh.md)
|
||||
322
docs/tutorial/Tables_zh.md
Normal file
322
docs/tutorial/Tables_zh.md
Normal file
@ -0,0 +1,322 @@
|
||||
# FunASR-1.x.x 注册模型教程
|
||||
|
||||
1.0版本的设计初衷是【**让模型集成更简单**】,核心feature为注册表与AutoModel:
|
||||
|
||||
* 注册表的引入,使得开发中可以用搭积木的方式接入模型,兼容多种task;
|
||||
|
||||
* 新设计的AutoModel接口,统一modelscope、huggingface与funasr推理与训练接口,支持自由选择下载仓库;
|
||||
|
||||
* 支持模型导出,demo级别服务部署,以及工业级别多并发服务部署;
|
||||
|
||||
* 统一学术与工业模型推理训练脚本;
|
||||
|
||||
|
||||
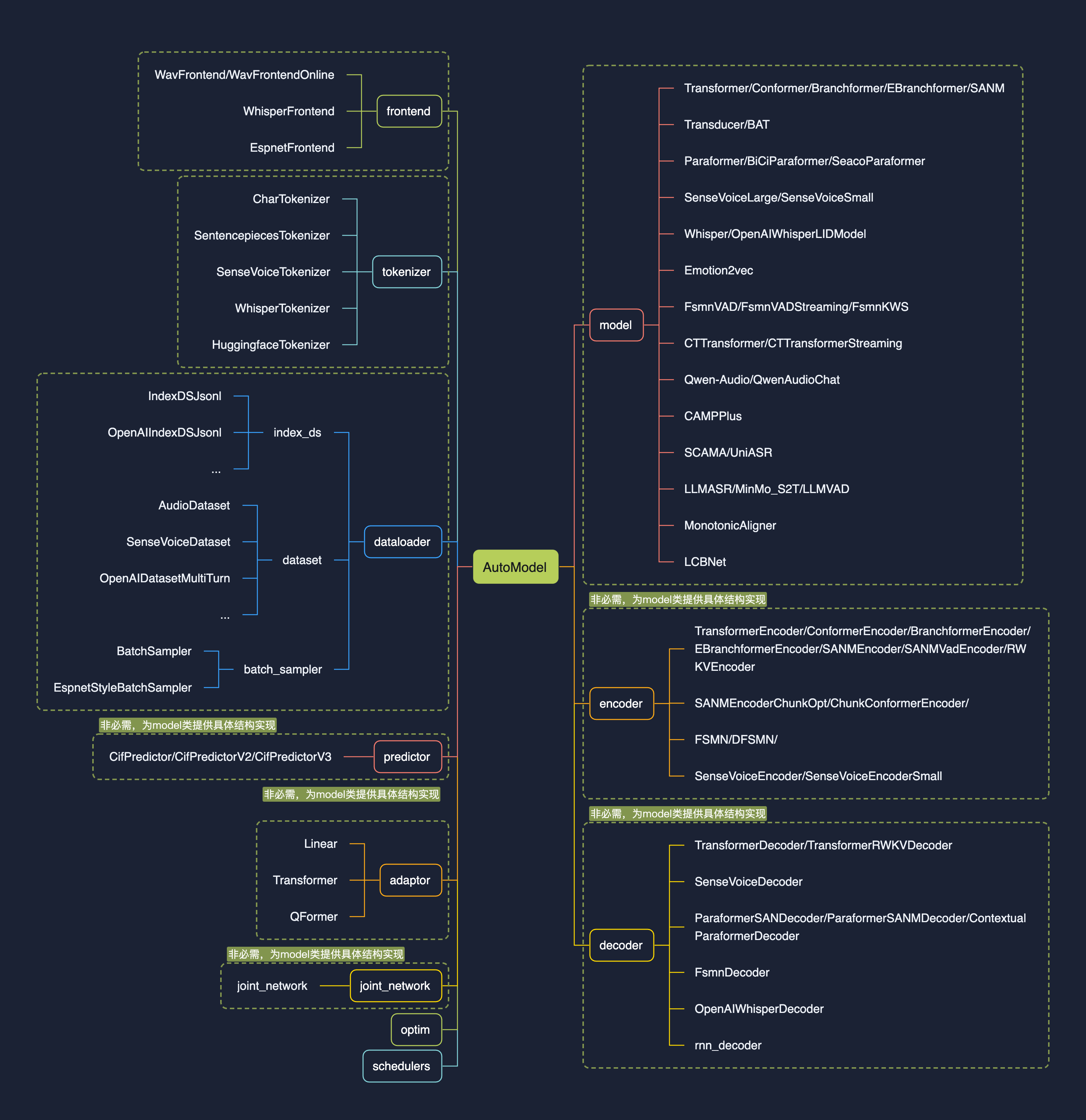
|
||||
|
||||
# 快速上手
|
||||
|
||||
## 基于automodel用法
|
||||
|
||||
### Paraformer模型
|
||||
|
||||
输入任意时长语音,输出为语音内容对应文字,文字具有标点断句,字级别时间戳,以及说话人身份。
|
||||
|
||||
```python
|
||||
from funasr import AutoModel
|
||||
|
||||
model = AutoModel(model="paraformer-zh",
|
||||
vad_model="fsmn-vad",
|
||||
vad_kwargs={"max_single_segment_time": 60000},
|
||||
punc_model="ct-punc",
|
||||
# spk_model="cam++"
|
||||
)
|
||||
wav_file = f"{model.model_path}/example/asr_example.wav"
|
||||
res = model.generate(input=wav_file, batch_size_s=300, batch_size_threshold_s=60, hotword='魔搭')
|
||||
print(res)
|
||||
```
|
||||
|
||||
### SenseVoiceSmall模型
|
||||
|
||||
输入任意时长语音,输出为语音内容对应文字,文字具有标点断句,支持中英日粤韩5中语言。【字级别时间戳,以及说话人身份】后续会支持。
|
||||
|
||||
```python
|
||||
from funasr import AutoModel
|
||||
from funasr.utils.postprocess_utils import rich_transcription_postprocess
|
||||
|
||||
model = AutoModel(
|
||||
model="iic/SenseVoiceSmall",
|
||||
vad_model="fsmn-vad",
|
||||
vad_kwargs={"max_single_segment_time": 30000},
|
||||
device="cuda:0",
|
||||
)
|
||||
|
||||
res = model.generate(
|
||||
input=f"{model.model_path}/example/en.mp3",
|
||||
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
|
||||
use_itn=True,
|
||||
batch_size_s=60,
|
||||
)
|
||||
text = rich_transcription_postprocess(res[0]["text"])
|
||||
print(text) #👏Senior staff, Priipal Doris Jackson, Wakefield faculty, and, of course, my fellow classmates.I am honored to have been chosen to speak before my classmates, as well as the students across America today.
|
||||
```
|
||||
|
||||
## API文档
|
||||
|
||||
#### AutoModel 定义
|
||||
|
||||
```plaintext
|
||||
model = AutoModel(model=[str], device=[str], ncpu=[int], output_dir=[str], batch_size=[int], hub=[str], **kwargs)
|
||||
```
|
||||
|
||||
* `model`(str): [模型仓库](https://github.com/alibaba-damo-academy/FunASR/tree/main/model_zoo) 中的模型名称,或本地磁盘中的模型路径
|
||||
|
||||
* `device`(str): `cuda:0`(默认gpu0),使用 GPU 进行推理,指定。如果为`cpu`,则使用 CPU 进行推理
|
||||
|
||||
* `ncpu`(int): `4` (默认),设置用于 CPU 内部操作并行性的线程数
|
||||
|
||||
* `output_dir`(str): `None` (默认),如果设置,输出结果的输出路径
|
||||
|
||||
* `batch_size`(int): `1` (默认),解码时的批处理,样本个数
|
||||
|
||||
* `hub`(str):`ms`(默认),从modelscope下载模型。如果为`hf`,从huggingface下载模型。
|
||||
|
||||
* `**kwargs`(dict): 所有在`config.yaml`中参数,均可以直接在此处指定,例如,vad模型中最大切割长度 `max_single_segment_time=6000` (毫秒)。
|
||||
|
||||
|
||||
#### AutoModel 推理
|
||||
|
||||
```plaintext
|
||||
res = model.generate(input=[str], output_dir=[str])
|
||||
```
|
||||
|
||||
* wav文件路径, 例如: asr\_example.wav
|
||||
|
||||
* pcm文件路径, 例如: asr\_example.pcm,此时需要指定音频采样率fs(默认为16000)
|
||||
|
||||
* 音频字节数流,例如:麦克风的字节数数据
|
||||
|
||||
* wav.scp,kaldi 样式的 wav 列表 (`wav_id \t wav_path`), 例如:
|
||||
|
||||
|
||||
```plaintext
|
||||
asr_example1 ./audios/asr_example1.wav
|
||||
asr_example2 ./audios/asr_example2.wav
|
||||
|
||||
```
|
||||
|
||||
在这种输入
|
||||
|
||||
* 音频采样点,例如:`audio, rate = soundfile.read("asr_example_zh.wav")`, 数据类型为 numpy.ndarray。支持batch输入,类型为list: `[audio_sample1, audio_sample2, ..., audio_sampleN]`
|
||||
|
||||
* fbank输入,支持组batch。shape为\[batch, frames, dim\],类型为torch.Tensor,例如
|
||||
|
||||
* `output_dir`: None (默认),如果设置,输出结果的输出路径
|
||||
|
||||
* `**kwargs`(dict): 与模型相关的推理参数,例如,`beam_size=10`,`decoding_ctc_weight=0.1`。
|
||||
|
||||
|
||||
详细文档链接:[https://github.com/modelscope/FunASR/blob/main/examples/README\_zh.md](https://github.com/modelscope/FunASR/blob/main/examples/README_zh.md)
|
||||
|
||||
# 注册表详解
|
||||
|
||||
## 模型资源目录
|
||||
|
||||

|
||||
|
||||
**配置文件**:config.yaml
|
||||
|
||||
```yaml
|
||||
model: SenseVoiceLarge
|
||||
model_conf:
|
||||
lsm_weight: 0.1
|
||||
length_normalized_loss: true
|
||||
activation_checkpoint: true
|
||||
sos: <|startoftranscript|>
|
||||
eos: <|endoftext|>
|
||||
downsample_rate: 4
|
||||
use_padmask: true
|
||||
|
||||
encoder: SenseVoiceEncoder
|
||||
encoder_conf:
|
||||
input_size: 128
|
||||
attention_heads: 20
|
||||
linear_units: 1280
|
||||
num_blocks: 32
|
||||
dropout_rate: 0.1
|
||||
positional_dropout_rate: 0.1
|
||||
attention_dropout_rate: 0.1
|
||||
kernel_size: 31
|
||||
sanm_shfit: 0
|
||||
att_type: self_att_fsmn_sdpa
|
||||
downsample_rate: 4
|
||||
use_padmask: true
|
||||
max_position_embeddings: 2048
|
||||
rope_theta: 10000
|
||||
|
||||
frontend: WhisperFrontend
|
||||
frontend_conf:
|
||||
fs: 16000
|
||||
n_mels: 128
|
||||
do_pad_trim: false
|
||||
filters_path: null
|
||||
|
||||
tokenizer: SenseVoiceTokenizer
|
||||
tokenizer_conf:
|
||||
vocab_path: null
|
||||
is_multilingual: true
|
||||
num_languages: 8749
|
||||
|
||||
dataset: SenseVoiceDataset
|
||||
dataset_conf:
|
||||
index_ds: IndexDSJsonl
|
||||
batch_sampler: BatchSampler
|
||||
batch_type: token
|
||||
batch_size: 12000
|
||||
sort_size: 64
|
||||
max_token_length: 2000
|
||||
min_token_length: 60
|
||||
max_source_length: 2000
|
||||
min_source_length: 60
|
||||
max_target_length: 150
|
||||
min_target_length: 0
|
||||
shuffle: true
|
||||
num_workers: 4
|
||||
sos: ${model_conf.sos}
|
||||
eos: ${model_conf.eos}
|
||||
IndexDSJsonl: IndexDSJsonl
|
||||
|
||||
train_conf:
|
||||
accum_grad: 1
|
||||
grad_clip: 5
|
||||
max_epoch: 5
|
||||
keep_nbest_models: 200
|
||||
avg_nbest_model: 200
|
||||
log_interval: 100
|
||||
resume: true
|
||||
validate_interval: 10000
|
||||
save_checkpoint_interval: 10000
|
||||
|
||||
optim: adamw
|
||||
optim_conf:
|
||||
lr: 2.5e-05
|
||||
|
||||
scheduler: warmuplr
|
||||
scheduler_conf:
|
||||
warmup_steps: 20000
|
||||
|
||||
```
|
||||
|
||||
**模型参数**:model.pt
|
||||
|
||||
**路径解析**:configuration.json
|
||||
|
||||
```json
|
||||
{
|
||||
"framework": "pytorch",
|
||||
"task" : "auto-speech-recognition",
|
||||
"model": {"type" : "funasr"},
|
||||
"pipeline": {"type":"funasr-pipeline"},
|
||||
"model_name_in_hub": {
|
||||
"ms":"",
|
||||
"hf":""},
|
||||
"file_path_metas": {
|
||||
"init_param":"model.pt",
|
||||
"config":"config.yaml",
|
||||
"tokenizer_conf": {"vocab_path": "tokens.tiktoken"},
|
||||
"frontend_conf":{"filters_path": "mel_filters.npz"}}
|
||||
}
|
||||
```
|
||||
|
||||
## 注册表
|
||||
|
||||
### 查看注册表
|
||||
|
||||
```python
|
||||
from funasr.register import tables
|
||||
|
||||
tables.print()
|
||||
```
|
||||
|
||||
支持查看指定类型的注册表:`tables.print("model")`
|
||||
|
||||
|
||||
### 新注册
|
||||
|
||||
```python
|
||||
from funasr.register import tables
|
||||
|
||||
@tables.register("model_classes", "MinMo_S2T")
|
||||
class MinMo_S2T(nn.Module):
|
||||
def __init__(*args, **kwargs):
|
||||
...
|
||||
|
||||
def forward(
|
||||
self,
|
||||
**kwargs,
|
||||
):
|
||||
|
||||
def inference(
|
||||
self,
|
||||
data_in,
|
||||
data_lengths=None,
|
||||
key: list = None,
|
||||
tokenizer=None,
|
||||
frontend=None,
|
||||
**kwargs,
|
||||
):
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
在config.yaml中指定新注册模型
|
||||
|
||||
```yaml
|
||||
model: MinMo_S2T
|
||||
model_conf:
|
||||
...
|
||||
```
|
||||
|
||||
## 注册原则
|
||||
|
||||
* Model:模型之间互相独立,每一个模型,都需要在funasr/models/下面新建一个模型目录,不要采用类的继承方法!!!不要从其他模型目录中import,所有需要用到的都单独放到自己的模型目录中!!!不要修改现有的模型代码!!!
|
||||
|
||||
* dataset,frontend,tokenizer,如果能复用现有的,直接复用,如果不能复用,请注册一个新的,再修改,不要修改原来的!!!
|
||||
|
||||
|
||||
# 独立仓库
|
||||
|
||||
可以作为独立仓库存在,用于代码保密,或者独立开源。基于注册机制,无需集成到funasr中,使用funasr进行推理,也可以直接进行推理,同样支持finetune
|
||||
|
||||
**使用AutoModel进行推理**
|
||||
|
||||
```python
|
||||
from funasr import AutoModel
|
||||
|
||||
# trust_remote_code:`True` 表示 model 代码实现从 `remote_code` 处加载,`remote_code` 指定 `model` 具体代码的位置(例如,当前目录下的 `model.py`),支持绝对路径与相对路径,以及网络 url。
|
||||
model = AutoModel(
|
||||
model="iic/SenseVoiceSmall",
|
||||
trust_remote_code=True,
|
||||
remote_code="./model.py",
|
||||
)
|
||||
```
|
||||
|
||||
**直接进行推理**
|
||||
|
||||
```python
|
||||
from model import SenseVoiceSmall
|
||||
|
||||
m, kwargs = SenseVoiceSmall.from_pretrained(model="iic/SenseVoiceSmall")
|
||||
m.eval()
|
||||
|
||||
res = m.inference(
|
||||
data_in=f"{kwargs ['model_path']}/example/en.mp3",
|
||||
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
|
||||
use_itn=False,
|
||||
ban_emo_unk=False,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
print(text)
|
||||
```
|
||||
|
||||
微调参考:[https://github.com/FunAudioLLM/SenseVoice/blob/main/finetune.sh](https://github.com/FunAudioLLM/SenseVoice/blob/main/finetune.sh)
|
||||
Loading…
Reference in New Issue
Block a user